一般に「ビッグデータ」とは、ボリューム(Volume:大量性)、バラエティ(Variety:多様性)、ベロシティ(Velocity:高速性)という3つのVによって特徴づけられる概念と言われています。
近年、このビッグデータを活用する技術、すなわち多様で大量のデータが高速に生成される環境においてその多様で大量のデータから価値ある情報を抽出して活用する技術の有用性が広く認識されつつあり、欧米や日本を代表する各企業が技術開発と市場開発にしのぎを削っていると言われています。
1.ビッグデータのデータ量
図1は、市場規模を測る指標として、日本の企業内外に設置されているサーバのデータ蓄積量の推計を図示したものです。
日本において企業が蓄積しているデータの蓄積量は、2012年の時点において約9.7EB(エクサバイト)と推定されています。
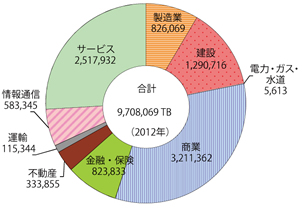
▲図1 日本におけるデータ蓄積量(単位:TB)
2.ビッグデータの活用事例の動向
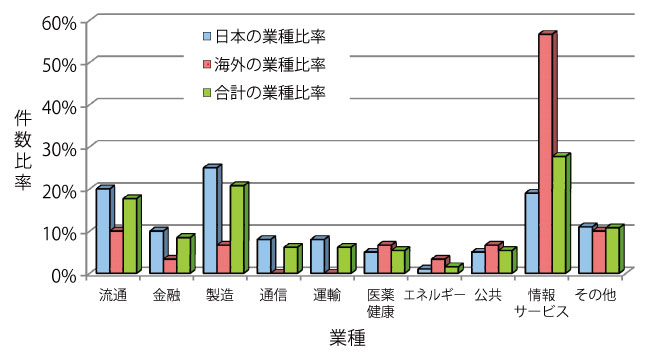
図2は、活用事例の業種別比率を図示したものです。また図3は、活用事例の対象データ別比率を図示したものです。
業種別比率では、日本では製造業、流通業の比率が高くなっているのに対し、海外では情報サービス業の比率が高くなっています。
対象データ別比率では、日本ではその他行動ログ、購買行動の比率が高いのに対し、海外ではオープンデータ、ソーシャルデータの比率が高くなっています。またセンサデバイスデータの活用事例比率は、日本と海外でほぼ同じ比率になっています。
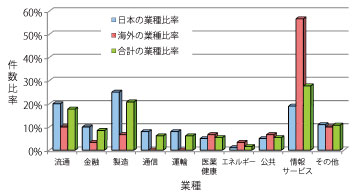
▲図2 活用事例の業種別比率 |

▲図3 活用事例の対象データ別比率 |
1.出願先国別の特許出願動向
図4は、2000年〜2011年に日本、米国、欧州、中国、韓国へ出願されたビッグデータ技術関連の特許出願について、出願先国別の出願件数の比率を図示したものです。
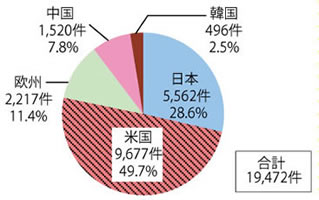
▲図4 出願先国別の出願件数比率
それぞれの国への特許出願件数の比率を観ると、米国への出願が全体の49.7%と最も大きく、次いで日本への出願が28.6%、欧州への出願が11.4%、中国への出願が7.8%、韓国への出願が2.5%となっています。また米国への出願と日本への出願とで全体の3/4以上を占めています。
2.技術区分別の特許出願動向
出願件数全体としては、2008年までは増加傾向でしたが、その後は横ばいの傾向を示しています。
技術区分ごとに観ると、データ解析技術と分析基盤技術の出願が比較的多くなされていると言えます。ここでデータ解析技術は、例えばテキストマイニング、リンクマイニング等のマイニング技術、OLAP(オンライン分析処理)等です。また分析基盤技術は、例えば分散ファイルシステム、分散データベース、分散ストレージ、分散並列処理等です。
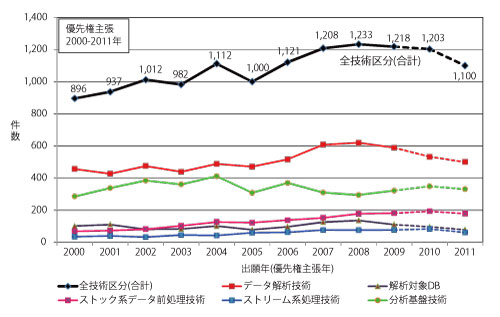
▲図5 技術区分別の出願件数推移
3.注目技術に関連する特許出願
表1は、ビッグデータ分析の注目技術に関連する特許の一覧です。
■表1 注目技術に関連する特許の一覧
| 番号 |
技術区分 |
技術名 |
代表的関連特許
|
発明の名称 |
優先権主張日 |
譲受人 |
| 1 |
データ
解析
技術 |
Apriori
(相関ルールマイニングアルゴリズム) |
US5794209A |
System and method for quickly mining association rules in databases |
1995-03-31 |
アイ・ビー・エム (米国) |
| 2 |
プライバシ
保護マイニング |
US6546389B1 |
Method and system for building a decision-tree classifier from privacy-preserving data |
2000-01-19 |
アイ・ビー・エム (米国) |
| 3 |
頻出パターンマイニング |
US6665669B2 |
Method and system for mining frequent patterns |
2000-01-03 |
サイモン・フレーザー大学(カナダ) |
| 4 |
解析用
DB |
Pig
(高級手続型クエリ言語) |
US6665669B2 |
Generating example data for testing database queries |
2008-01-16 |
ヤフー(米国) |
| 5 |
匿名化 |
k-匿名化 |
US20020169793A1 |
Systems and methods for deidentifying entries in a data source |
2001-04-10 |
カーネギーメロン大学(米国) |
| 6 |
分析
基盤
技術 |
Paxos
(分散処理用プロトコル) |
US5261085A |
Fault-tolerant system and method for implementing a distributed state machine |
1989-06-23 |
ヒューレット・パッカード(米国) |
| 7 |
Google File System
(分散ファイルシステム) |
US7065618B1 |
Leasing scheme for data-modifying operations |
2003-02-14 |
グーグル(米国) |
| 8 |
MapReduce
(並列分散処理基盤) |
US7650331B1 |
System and method for efficient large-scale data processing |
2004-06-18 |
グーグル(米国) |
| 9 |
BigTable(分散キー・バリュー・ストア) |
US7428524B2 |
Large scale data storage in sparse tables |
2005-08-05 |
グーグル(米国) |
| 10 |
Dynamo
(分散データベース) |
US7925624B2 |
System and method for providing high availability data |
2006-03-31 |
アマゾン テクノロジーズ(米国) |
| 11 |
PNUTS
(分散データベース) |
US20090144333A1 |
SYSTEM FOR MAINTAINING A DATABASE |
2007-11-30 |
ヤフー(米国) |
| 12 |
Pregel
(グラフ処理) |
US8510538B1 |
System and method for limiting the impact of stragglers in large-scale parallel data processing |
2009-04-13 |
グーグル(米国) |
データ解析技術の1つとして、相関ルールマイニングアルゴリズムが挙げられます(表1の番号1)。これは例えばデータベースに記憶された消費者取引の品目セットのうち最小支持値と称されるユーザ定義による最小回数でデータベースに現れる品目セットを大品目セットとして識別し、データベース中に各大品目セットの現れる回数とデータベース中に品目セットの特定のサブセットの現れる回数との比を比較することにより品目セット間の相関法則を発見し、この比が所定の最低信頼値を超えるとき、消費者の購買傾向を表す相関法則を出力する、というものです。
また分析基盤技術の1つとして、MapReduce等の並列分散処理技術が挙げられます(表1の番号8)。これは多数のコンピューター(ノード)の集合であるコンピュータ・クラスター又はグリッドを用いてデータを並列処理する技術です。例えばMapReduceは、マスターノードが入力データを分割して複数のスレーブノードに独立かつ並列に処理させ(Mapステップ)、複数のスレーブノードの処理結果をマスターノードが集約して何らかの目的に対する結果を出力する(Reduceステップ)ことによって、大規模なデータを並列に分散処理します。
さらに分析基盤技術の1つとして、Dynamo、PNUTS等の分散データベース技術が挙げられます(表1の番号10、11)。分散データベース技術とは、複数のサーバに分散されている複数のデータベースを単一のデータベースとして取り扱えるようにする技術です。
4.オープン特許非係争誓約
米国グーグル社は、2013年3月、MapReduce関連の特許を含む10件の特許について、オープン特許非係争誓約を発表しました。これは、これらの特許権については、オープンソースソフトウェア又はフリーソフトウェアで利用される限り、開発者との間で特許係争を起こさないことを誓約するものです。
このオープン特許非係争誓約は、オープンソースソフトウェアの開発と導入の促進、特許訴訟の低減等を目的とするものであり、今後、このような動きは広がっていく可能性があるのではないかと思われます。
出典:特許庁ウェブサイト
平成25年度 特許出願技術動向調査報告書 ビッグデータ分析技術
http://www.jpo.go.jp/shiryou/pdf/gidou-houkoku/25_bigdata.pdf
監修:特許業務法人ナガトアンドパートナーズ